
对象存储支持海量的数据存储,腾讯云对象存储COS单个存储桶理论上支持无限数目的文件,实际生产中,单个桶的文件数目可达数十亿、数百亿甚至数千亿。这么大量级的存储量,给我们去分析存储桶中数据文件的分布、单个目录下总文件数及文件大小、特定后缀文件的数目和大小等场景,带来了极大的困难。例如在海量数据的场景下统计某个目录(对象前缀)下所有文件的大小,只能列出该目录下所有文件,然后将所有文件大小相加的方式获取总大小,根据客户的实际反馈,在文件数目非常大的情况下,这种方式不是特别友好,耗时非常久,还需要长期占有主机端资源做list object以及统计容量操作。
如果对于容量统计的时效性要求不高,可以采用清单的方式。COS支持每天、每周生成一次清单以及即时清单,清单中包含了存储桶中所有对象的列表以及每个对象对应的一些信息,包括每个对象的大小。清单生成之后,将会以多个压缩之后的csv文件的方式存放在COS上,我们可以使用腾讯云数据湖计算(DLC)引擎直接分析存放在COS上的清单文件。
1、生成清单
参考如下文档查看清单的描述以及如何配置清单:
对象存储 清单功能概述 – 开发者指南 – 文档中心 – 腾讯云 (tencent.com)
对象存储 开通清单功能 – 控制台指南 – 文档中心 – 腾讯云 (tencent.com)
用户配置一项清单任务后,COS 将根据配置定时扫描用户存储桶内指定的对象,并输出一份清单报告,清单报告支持 CSV 格式文件。目前 COS 清单报告中支持记录以下信息:
| 清单信息 | 描述 |
| AppID | 账号的 ID |
| Bucket | 执行清单任务的存储桶的名称 |
| fileFormat | 文件格式 |
| listObjectCount | 列出的对象数量 |
| listStorageSize | 列出的对象大小 |
| filterObjectCount | 筛选的对象数量 |
| filterStorageSize | 筛选的对象大小 |
| Key | 存储桶中的对象文件名称。使用 CSV 文件格式时,对象文件名称采用 URL 编码形式,必须解码然后才能使用 |
| VersionId | 对象版本 ID。在存储桶上启用版本控制后,COS 会为添加到存储桶的对象指定版本号。如果列表仅针对对象的当前版本,则不包含此字段 |
| IsLatest | 如果对象的版本为最新,则设置为 True。如果列表仅针对对象的当前版本,则不包含此字段 |
| IsDeleteMarker | 如果对象是删除标记,则设置为 True。如果列表仅针对对象的当前版本,则不包含此字段 |
| Size | 对象大小(以字节为单位) |
| LastModifiedDate | 对象的最近修改日期(以日期较晚者为准) |
| ETag | 实体标签是对象的哈希。ETag 仅反映对对象的内容的更改,而不反映对对象的元数据的更改。ETag 可能是也可能不是对象数据的 MD5 摘要。是与不是取决于对象的创建方式和加密方式 |
| StorageClass | 用于存储对象的存储类,有关更多信息,请参见 存储类型 |
| IsMultipartUploaded | 如果对象以分块上传形式上传,则设置为 True,有关更多信息,请参见 分块上传 |
| Replicationstatus | 设置为 PENDING、COMPLETED、FAILED 或 REPLICA。有关更多信息,请参见 跨地域复制行为说明 |
清单报告及相关的 Manifest 相关文件会发布在目标存储桶中,其中清单报告会发布在以下路径:
destination-prefix/appid/source-bucket/config-ID/YYYYMMDD/manifest.json
destination-prefix/appid/source-bucket/config-ID/YYYYMMDD/manifest.checksum有关 Mainfest 文件的介绍如下:
- manifest.json 和 manifest.chenksum 都属于 Manifest 文件,manifest.json 描述清单报告的位置,manifest.checksum 是作为 manifest.json 文件内容的 MD5。每次交付新的清单报告时,均会带有一组新的 Manifest 文件。
- manifest.json 包含的每个 Manifest 均提供了有关清单的元数据和其他基本信息,这些信息包括:
- 源存储桶名称。
- 目标存储桶名称。
- 清单版本。
- 时间戳,包含生成清单报告时开始扫描存储桶的日期与时间。
- 清单文件的格式与架构。
- 目标存储桶中清单报告的对象键,大小及 md5Checksum。
以下是一个参考的manifest.json文件。
{
"sourceAppid": "125xxxxx",
"sourceBucket": "examplebucket",
"destinationAppid": "125xxxxx",
"destinationBucket": "examplebucket",
"fileFormat": "CSV",
"listObjectCount": "4915",
"listStorageSize": "34659527588",
"filterObjectCount": "4915",
"filterStorageSize": "34659527588",
"fileSchema": "Appid, Bucket, Key, Size, LastModifiedDate, ETag, StorageClass, IsMultipartUploaded, ReplicationStatus, Tag",
"files": [
{
"key": "cos_bucket_inventory/1253960454/examplebucket/instant_instant_20220517120608/data/55cb8f79a304fed2daad4564358780e1.csv.gz",
"size": "164745",
"md5Checksum": "e9fabcef4afff3b71661169ab4a092a9"
}
]
}
- 创建DLC外表
腾讯云数据湖计算 DLC(Data Lake Compute,DLC)提供了敏捷高效的数据湖分析与计算服务。该服务采用无服务器架构(Serverless)设计,用户无需关注底层架构或维护计算资源,使用标准 SQL 即可完成对象存储服务(COS)及其他云端数据设施的联合分析计算。借助该服务,用户无需进行传统的数据分层建模,大幅缩减了海量数据分析的准备时间,有效提升了企业数据敏捷度。
DLC简单易用,参考https://cloud.tencent.com/document/product/1342/72493文档实现一分钟完成COS对象存储上的数据分析。
下面是在DLC上创建外部表的过程:
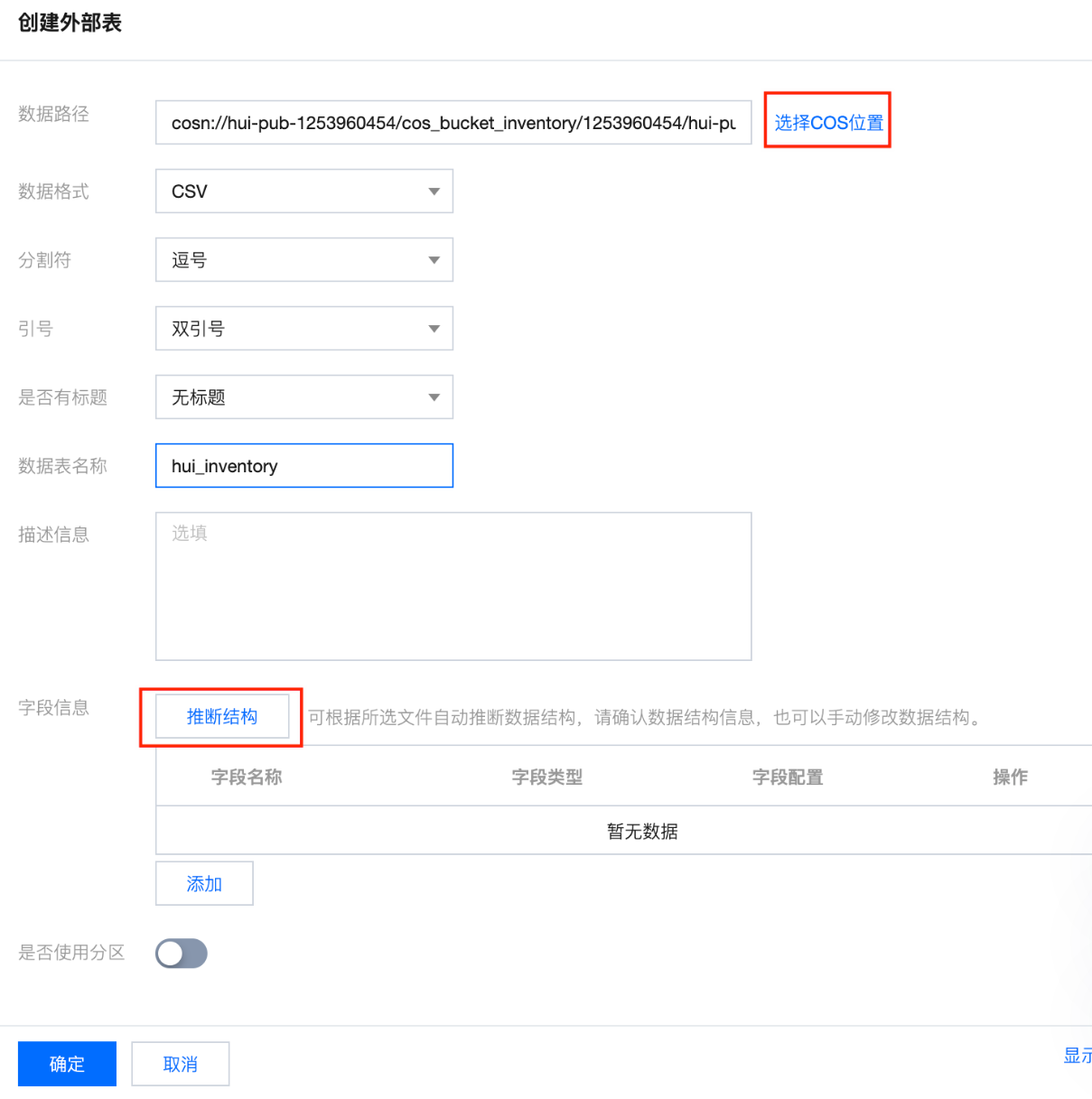
上图中,通过“选择COS位置”按钮,浏览到COS上存放所有清单文件的路径,DLC会自动扫描目录下的所有的文件做查询。
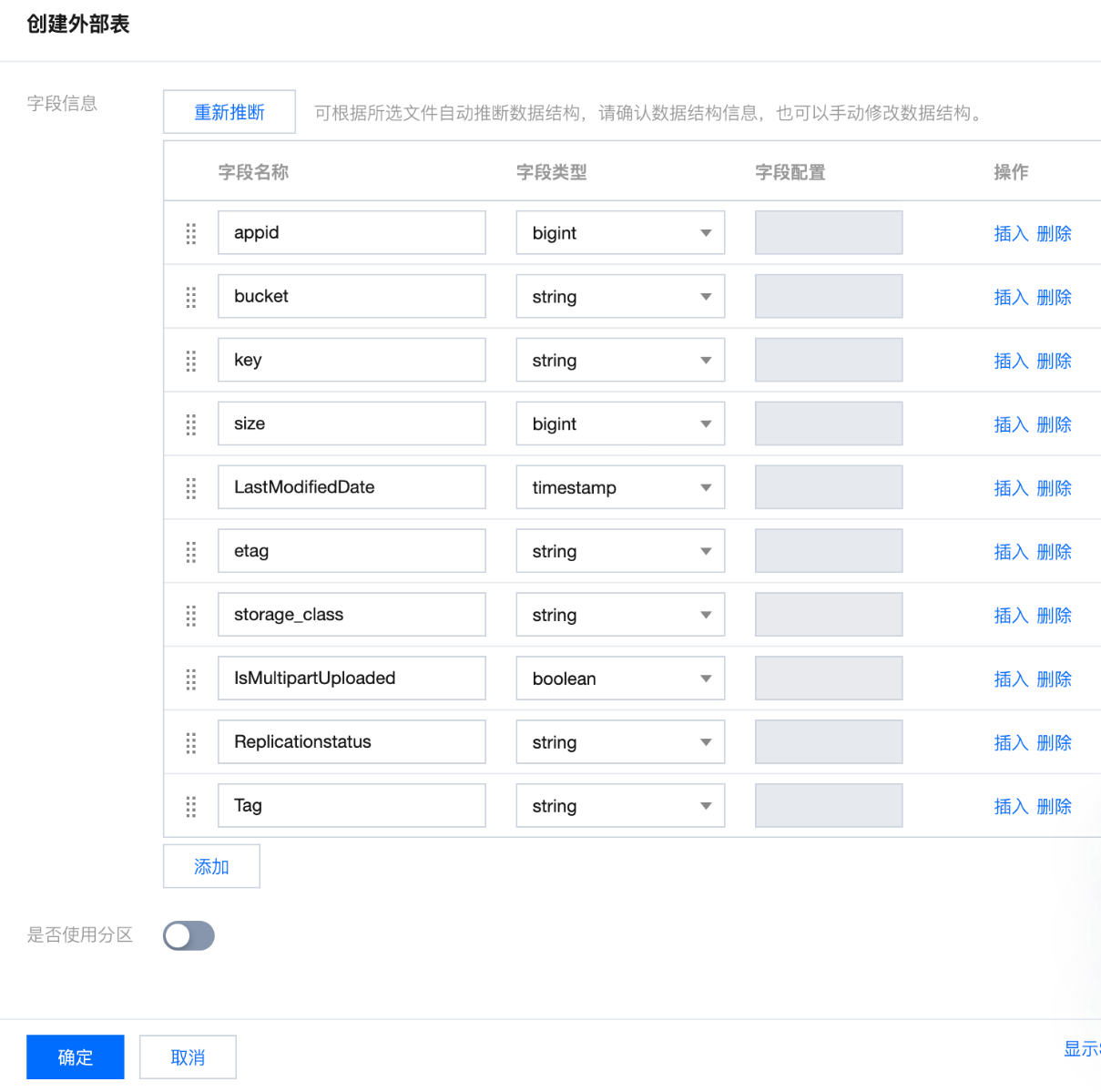
创建表的字段信息,参考清单manifest.json文件中的”fileSchema”字段:
"fileSchema": "Appid, Bucket, Key, Size, LastModifiedDate, ETag, StorageClass, IsMultipartUploaded, ReplicationStatus, Tag"
- 清单分析查询
在DLC控制台,创建新的查询请求,并在右上角选择查询引擎,即可开始对COS上的数据进行分析:
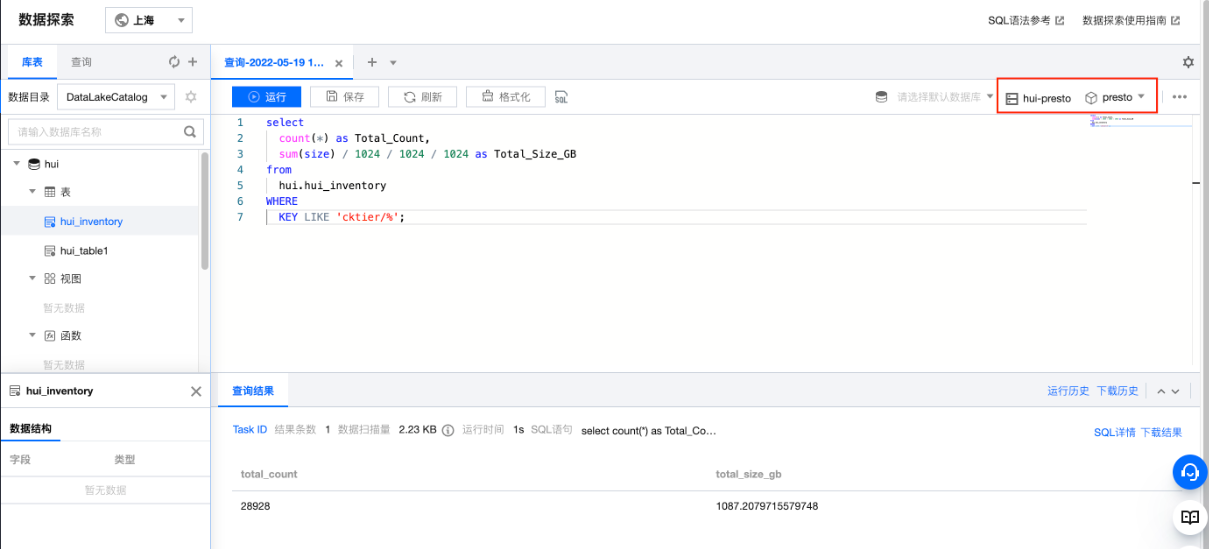
上述查询,分析了存储桶中,以cktier/为前缀的对象的总数目以及总的大小。
(本示例中使用了Presto作为分析引擎,如果分析的清单数据量较大,也可采用Spark引擎)
以下是一些常用场景的查询分析SQL语句。
统计prefix/前缀的所有对象总数目及总容量大小:
select count(*) as Total_Count, sum(size) / 1024 / 1024 / 1024 as Total_Size_GBfrom hui.hui_inventoryWHERE KEY LIKE 'prefix/%';
统计所有后缀名为mp4(不区分大小写)的文件总数目及总容量大小:
select count(*) as Total_Count, sum(size) / 1024 / 1024 / 1024 as Total_Size_GBfrom hui.hui_inventoryWHERE lower(KEY) LIKE '%.mp4';
统计所有后缀名为mp3(不区分大小写)且修改时间是最近180天的文件总数目及总容量大小:
select count(*) as Total_Count, sum(size) / 1024 / 1024 / 1024 as Total_Size_GBfrom hui.hui_inventoryWHERE lower(KEY) LIKE '%.mp3' AND ( to_unix_timestamp(localtimestamp()) - to_unix_timestamp( replace(lastmodifieddate, 'T', ' '), 'yyyy-MM-dd HH:mm:ss+08:00' ) ) / 3600 / 24 < 180;