1 ClickHouse简介
ClickHouse是一个用于联机分析(OLAP)的列式数据库管理系统(DBMS),支持PB级数据量的交互式分析,ClickHouse最初是为YandexMetrica 世界第二大Web分析平台而开发的。多年来一直作为该系统的核心组件被该系统持续使用着。目前为止,该系统在ClickHouse中有超过13万亿条记录,并且每天超过200多亿个事件被处理。它允许直接从原始数据中动态查询并生成报告。自2016 年开源以来,ClickHouse 凭借其数倍于业界顶尖分析型数据库的极致性能,成为交互式分析领域的后起之秀,发展速度非常快。
更详细的ClickHouse特性,可以参考ClickHouse的官方文档:
https://clickhouse.tech/docs/zh/introduction/distinctive-features/
2 ClickHouse的架构简述
ClickHouse是一种分布式的数据库管理系统,不同于其他主流的大数据组件,它并没有采用Hadoop生态的HDFS文件系统,而是将数据存放于服务器的本地盘,同时使用数据副本的方式来保障数据的高可用性。
ClickHouse使用分布式表实现数据的分布式存储和查询。下图演示了一个分布式表是如何存储的:
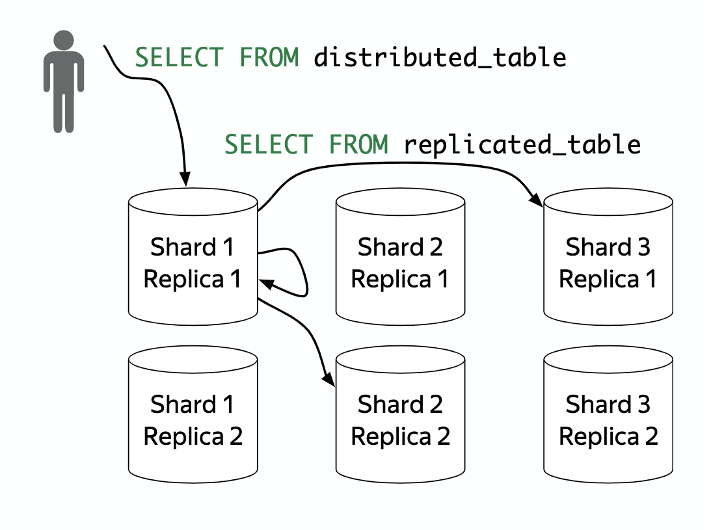
分片(Shard):包含数据的不同部分的服务器,要读取所有数据必须访问所有的分片。通过将分布式表的数据存放到多个Shard实现计算和存储的横向扩展。
副本(Replica):每个切片的数据都包含多个副本,要读取数据时访问任一副本上的数据即可。通过副本机制保证存储数据的单节点失效时数据的可用性。只有MergeTree类型的表引擎可以支持多副本。ClickHouse是在表的引擎而不是数据库引擎实现数据的副本功能的,所以副本是表级别的而不是服务器级别的。数据在插入ReplicatedMergeTree引擎的表的时候会做数据的主备同步以实现数据的多副本,在同步的过程中使用ZooKeeper做分布式协调。
分布式表(Distributed table):使用分布式引擎创建的分布式表并不存储数据,但是能够将查询任务分布到多台服务器上处理。在创建分布式表的过程中,ClickHouse会先再每个Shard上创建本地表,本地表只在对应的节点内可见,然后再将创建的本地表映射给分布式表。这样用户在访问分布式表的时候,ClickHouse会自动根据集群的架构信息,将请求转发给对应的本地表。
综上所述,一个ClickHouse集群由分片组成,而每个分片又由多个数据副本组成。一个副本对应了组成ClickHouse集群中的一个服务器节点,并使用该服务器节点上的本地盘存储数据。通过分布式表、数据分片以及数据副本,ClickHouse实现了集群的横向扩展能力并提供数据的高可用保护。
3 数据的分层存储
3.1 数据的分层存储
从19.15这个版本开始,ClickHouse开始支持multi-volume storage这个功能,它允许将ClickHouse表存储在包含多个设备的卷当中,利用这个特性,我们可以在volume中定义不同类型的磁盘,根据数据的“冷”、“热”程度将数据存放在不同类型的磁盘上(我们可以称之为Tier Storage),以实现性能与成本的平衡。
以下是Altinity网站上关于multi-volume storage的架构图:
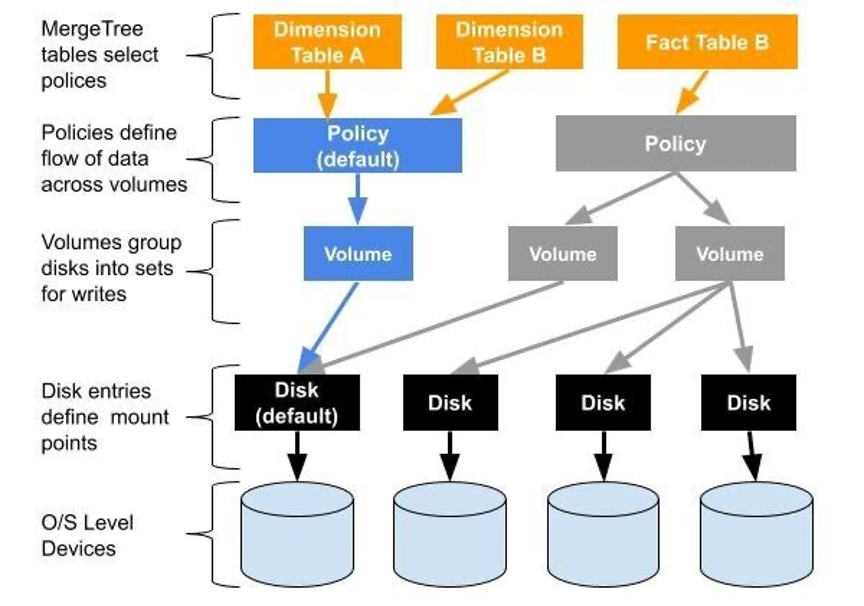
ClickHouse的配置文件中和磁盘相关的术语:
磁盘(Disk):已经格式化成文件系统的块设备。
默认磁盘(Default Disk):在服务器设置中通过path参数指定的数据存储,默认路径为/var/lib/clickhouse/。
卷(Volume):有序的磁盘的集合。
存储策略(Storage Policy):卷的集合以及卷之间数据移动的规则。
ClickHouse存储及存储相关的策略是写在配置文件中的,你可以在/etc/clickhouse-server/config.xml文件中添加关于卷、磁盘以及存储策略的定义,也可以在/etc/clickhouse-server/config.d目录中新建xml类型的配置文件,添加相关的存储的定义。
3.2 ClickHouse支持的磁盘类型
ClickHouse主要支持DiskLocal和DiskS3两种常用的磁盘类型。
3.2.1 DiskLocal类型磁盘
DiskLocal类型磁盘使用服务器本地磁盘,并指明数据存储的路径。ClickHouse有一个名为default的DiskLocal类型的磁盘,路径为/var/lib/clickhouse/。

同样我可以自定义新增DiskLocal类型的磁盘,在ClickHouse中新增一个DiskLocal类型的磁盘,使用路径问/data,步骤如下:
- 服务器新挂载一块硬盘,并格式化文件系统并挂载在/data目录下。
- 在/etc/clickhouse-server/config.d目录下新建一个名为storage.xml的文件,并添加如下内容:
<yandex>
<storage_configuration>
<disks>
<localdisk> <!-- disk name -->
<path>/data/</path>
</localdisk>
</disks>
<policies>
<local>
<volumes>
<main>
<disk>localdisk</disk>
</main>
</volumes>
</local>
</policies>
</storage_configuration>
</yandex>
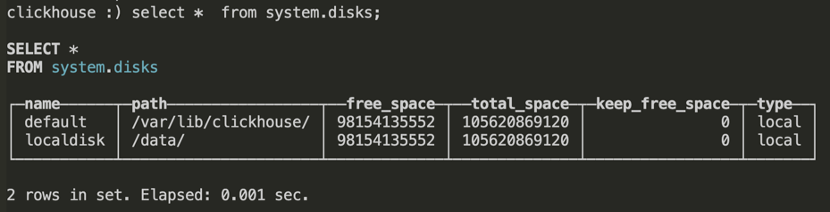
- 重启clickhouse-server服务之后,查看新加的磁盘:
3.2.2 DiskS3类型磁盘
ClickHouse支持DiskS3类型磁盘,使用S3接口访问存储于对象存储上的数据,原生支持AWS对象存储S3以及腾讯云对象存储COS。
下面我们在ClickHouse中再添加一个DiskS3类型的磁盘,这里我们使用腾讯云存储COS的一个存储桶作为例子,编辑/etc/clickhouse-server/config.d/storage.xml文件,内容如下:
<yandex>
<storage_configuration>
<disks>
<localdisk> <!-- disk name -->
<path>/data/</path>
</localdisk>
<cos>
<type>s3</type>
<endpoint>http://example-1250000000.cos.ap-shanghai.myqcloud.com/ck/</endpoint>
<access_key_id>AKIDxxxxxxxx</access_key_id>
<secret_access_key>xxxxxxxxxxx</secret_access_key>
</cos>
</disks>
<policies>
<local>
<volumes>
<main>
<disk>localdisk</disk>
</main>
</volumes>
</local>
<cos>
<volumes>
<main>
<disk>cos</disk>
</main>
</volumes>
</cos>
</policies>
</storage_configuration>
</yandex>
在上面的配置文件中,我们定义了两个磁盘,一个名为localdisk的Disklocal类型的磁盘,使用本地/data路径存储数据,另外一个是名为cos的DiskS3类型的磁盘,使用腾讯云对象存储的example-1250000000存储桶存储数据,并需要在配置文件中配置可以访问该存储桶账号的SecretId和SecretKey,上面的例子中access_key_id和secret_access_key分别对应访问COS存储桶账号的SecretId和SecretKey。接下来在策略中我们定义了两个策略用于将数据存储至本地磁盘或者对象存储COS。
在ClickHouse中重新加载配置后,能查询到刚才我们定义的磁盘及存储策略:
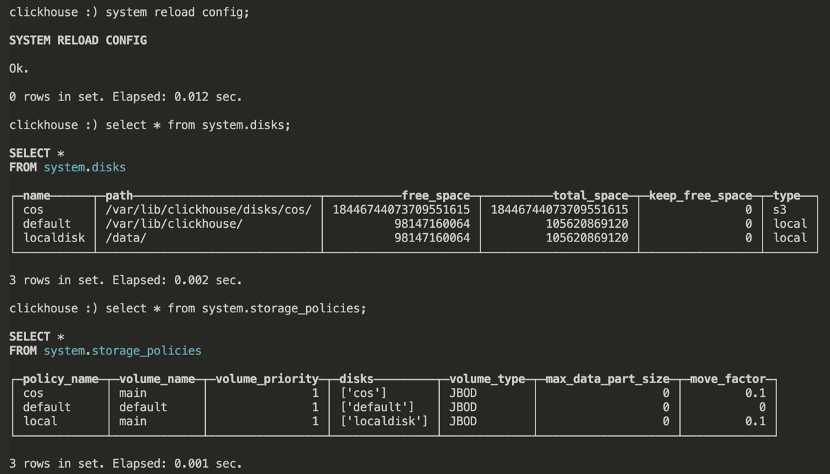
在后面的章节我们会详细演示如何将ClickHouse表中的数据存储在本地存储或者对象存储COS上。
3.3 数据移动策略
通过在配置文件中配置多个不同类型的磁盘以及存储策略,ClickHouse能够将数据存储在不同的存储介质中,同时ClickHouse还支持配置移动策略以实现数据在不同存储介质之间自动的移动。
3.3.1 基于move factor的数据移动策略
这是一种基于文件大小以及卷(volume)中各个磁盘(Disk)容量使用情况来移动数据的策略。
下面的例子中,我们建立了一个名为“moving_from_local_to_cos”的策略,在策略中我们定义了两种存储,第一个是名为“hot”的卷,这个卷中有一个名为localdisk的磁盘并设置这个磁盘上的文件最大值为1GB;第二个是名为“cold”的卷,这个卷中有一个名为cos的磁盘。
最后是move_factor参数,表示当卷的可用容量低于move_factor参数设定的值的时候,数据将被自动的移动到下一个卷,本例中当hot卷的容量低于30%的时候,hot卷中的数据将被自动的移动到cold卷。
<moving_from_local_to_cos>
<volumes>
<hot>
<disk>localdisk</disk>
<max_data_part_size_bytes>1073741824</max_data_part_size_bytes>
</hot>
<cold>
<disk>cos</disk>
</cold>
</volumes>
<move_factor>0.3</move_factor>
</moving_from_local_to_cos>
有一点需要强调的是,配置文件里各个卷的顺序非常重要,当ClickHouse有新数据写入的时候,数据会优先写入到第一个卷,再依次写入后面的卷。同时move factor的的移动策略也是将数据从前面的卷移动到后面的卷。所以我们在定义卷的时候,要把数据优先写入的卷放在配置文件的前面。在实际的使用场景中一般是把高性能存储放在前面,把高容量低成本的存储放在后面,这样实现新的热数据存放在高性能存储以获取极致的实时查询性能、老的历史冷数据存放在高容量存储以获取较低的存储成本以及较好的批量查询性能。
3.3.2 基于TTL的数据移动策略
ClickHouse支持表级别的TTL表达式,允许用户设置基于时间的规则,从而能够自动的在指定的磁盘或者卷之间移动数据,以实现了数据在不同的存储层之间的分层存储。下面列举了几种比较典型的TTL的写法,从例子我们可以看出,TTL表达式只是一个简单的SQL表达式,里边包含了时间以及时间的间隔,下面是TTL的一些例子:
TTL date_time + INTERVAL 1 MONTH
TTL date_time + INTERVAL 15 HOUR
TTL date_time + toIntervalMonth(ttl)
TTL date_time + toIntervalHour(ttl)
TTL date_time + INTERVAL ttl MONTH
TTL date_time + INTERVAL ttl HOUR
在新建表的时候,我们可以在建表的SQL语句后面加上TTL的表达式,用于根据TTL设置的时间策略在磁盘或者卷之间移动或者删除数据块。
TTL date_time + INTERVAL 6 MONTH DELETE,
date_time + INTERVAL 1 WEEK TO VOLUME 'localdisk',
date_time + INTERVAL 4 WEEK TO DISK 'cos';
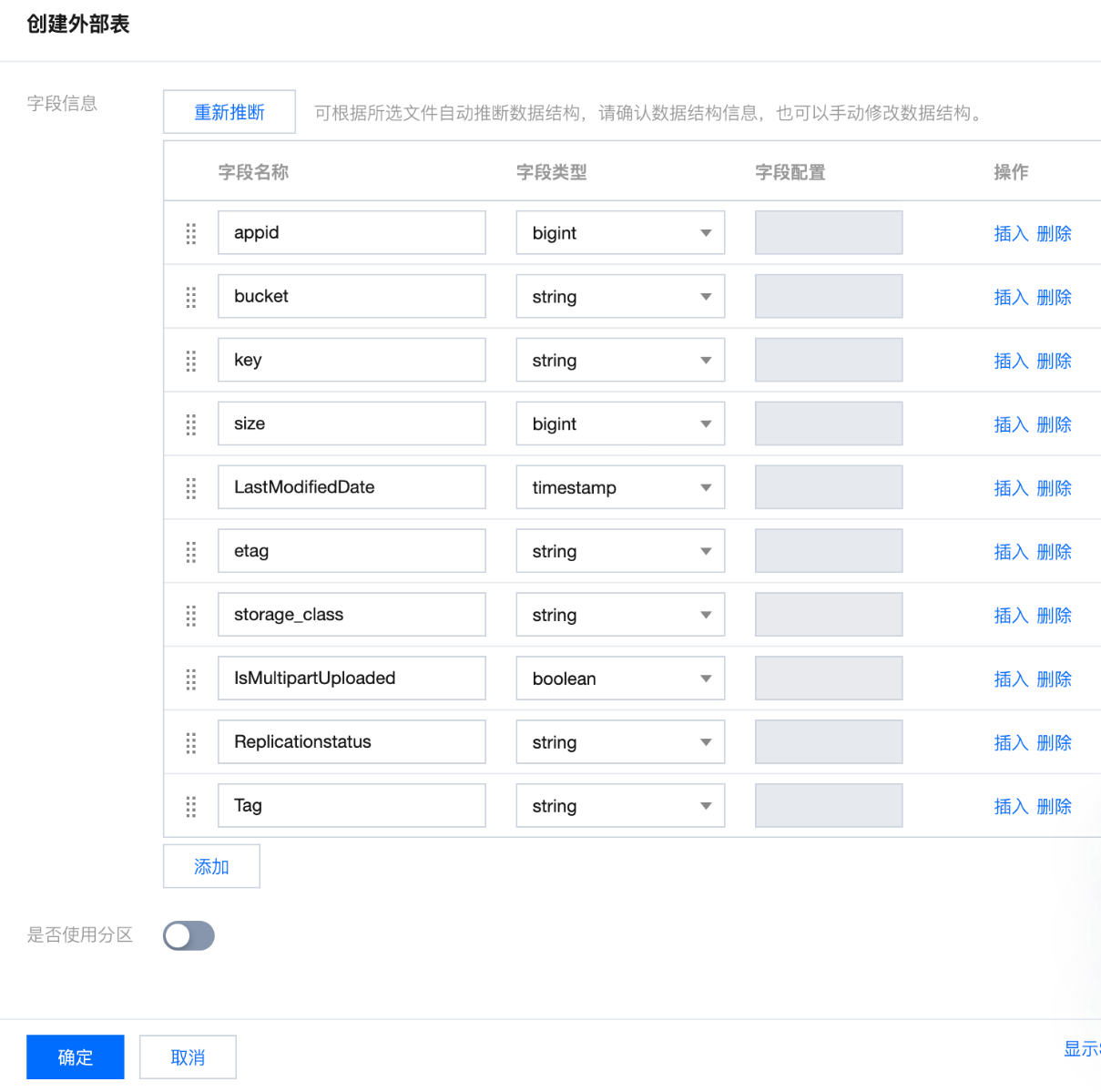
下面是一个完整的建表的语句,并配置了TTL,根据LastModifiedDate中的时间,默认将数据块放置到ttlhot卷,当LastModifiedDate的值超过三个月时将对应的数据块移动到ttlcold卷。
CREATE TABLE cos_inventory_ttl (
appid UInt64,
bucket String,
key String,
size UInt64,
LastModifiedDate DateTime,
etag String,
storage_class String,
IsMultipartUploaded String,
Replicationstatus String
) ENGINE = MergeTree()
ORDER BY LastModifiedDate
TTL LastModifiedDate to volume 'ttlhot',
LastModifiedDate + toIntervalMonth(3) TO VOLUME 'ttlcold'
SETTINGS
storage_policy='ttl',
index_granularity=8192;
4 基于腾讯云存储COS的分层存储实现
在前面的章节,我们介绍了ClickHouse分布式表的数据是如何存储、ClickHouse支持的磁盘类型以及如何配置数据在各类型存储中移动的策略,接下来我们来详细介绍一下如何利用ClickHouse的这些特性以及对象存储COS的优势来解决我们在使用ClickHouse中遇到的一些问题。
4.1 当前ClickHouse数据存储的问题
在和使用ClickHouse交流的时候,客户经常会有这样一个困扰:追求极致查询性能一般是客户选择使用ClickHouse的原因,所以客户一般会选择腾讯云的增强型SSD云硬盘存放ClickHouse的数据,用于提升查询的性能,但是增强型SSD云硬盘价格昂贵,综合性能及成本考虑,客户会选择将比较老的历史数据从ClickHouse中清除。虽然绝大多数的查询都集中在最新的数据上,但是业务方偶尔还是会有访问老的历史数据的需求,如何平衡成本以及业务方偶尔访问历史数据的需求成为ClickHouse系统管理者头疼的问题。
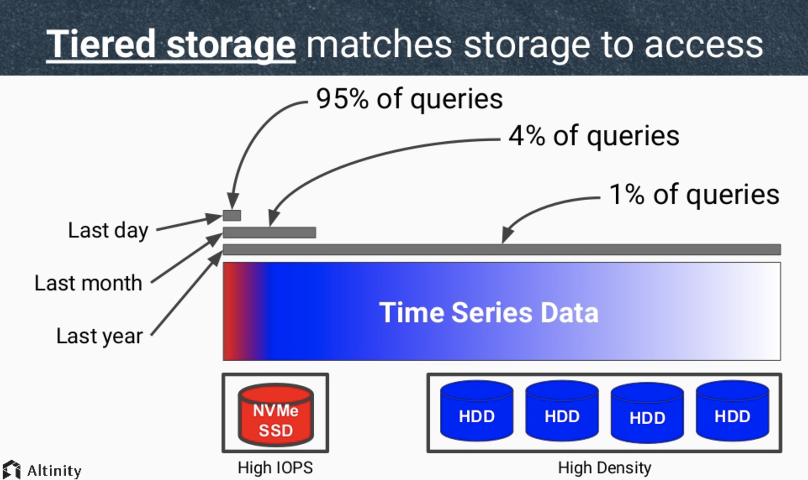
以上面提到的客户的困扰为例,根据业务方的需求,ClickHouse集群需要尽可能存储更长时间的数据,如果这些长时间保存的数据都存放在增强型SSD云盘上,成本将会非常的高。而在实际的业务场景中,可能有95%以上的查询交互都发生在最近一天生成的数据上,剩下5%的的任务都是发生在较早的数据上的批量查询任务,如果将大量的访问频率较低的历史数据都放在高成本的增强型SSD上,会造成极大的容量及性能的浪费。
下图是引用Altinity的一个ClickHouse在实际使用中关于查询频率和对应的数据时间的统计:
4.2 腾讯云存储COS的优势
对象存储COS是腾讯云存储产品,是无目录层次结构、无数据格式限制、无容量上限,支持 HTTP/HTTPS 协议访问的分布式存储服务。
COS以存储桶的方式组织数据,存储桶空间无容量上限,按需使用、按量计费、按需扩展。使用COS作为备份存储有如下优势:
- 按需使用按量结算:COS开服即用,开通即可用,登录腾讯云官网注册账号后,一键式开通COS服务,就可使用,无需建设成本。COS提供海量的存储空间,无需规划存储容量。COS提供按量付费的方式,避免资源浪费、降低使用成本。
- 高可靠高可用性:COS提供高达99.99%的服务可用性,以及高达12个9的数据持久性,为数据提供可靠的保障。
- 高性能:单个存储桶QPS可达30,000以及15Gbit/s带宽。
- 开放兼容:COS提供全兼容行业标杆AWS S3的接口,提供terrafrom等多种生态工具支持。
- 数据安全:COS提供多租户权限隔离,支持HTTPS加密传输,支持SSE-KMS加密等多种数据加密方式。
- 低成本:提供具有竞争力的产品定价,提供标准存储、低频存储以及归档存储三种类型,并支持数据生命周期管理,进一步降低云存储成本。
基于以上推腾讯云对象存储COS的优势,我们推荐使用腾讯云增强型SSD云盘以及腾讯云对象存储COS构建ClickHouse的分层存储结构。增强型SSD云盘存放最近时间生成并且访问频繁的“热数据”、COS存放较早时间生成且访问不频繁的“冷数据”,并在建表的时候使用TTL实现数据根据特定时间策略的自动沉降。
通过设置的数据分层策略,我们实现了将最新生成的、交互式查询频率较高的数据存放在高性能的增强型SSD云盘上,同时根据数据的访问场景设置策略,当数据不再被高频率交互式查询访问时将数据转移到高容量、低成本的二级存储上COS,在不牺牲交互式查询性能的情况下极大地降低了总体使用成本。
通过该方案我们能够同时兼顾以下各方面:
- 极致性能:最新的数据存放在增强型SSD云盘,为业务的即时查询提供极致性能 ;同时COS提供的高带宽、高并发为历史数据的批量查询提供了较高的性能。
- 超大容量:腾讯云对象存储COS提供了无容量上限的存储空间,将历史数据存放在COS上后,不用再担心磁盘空间不足删除数据后导致无法满足业务部门较早数据查询的需求。
- 低成本:相对于本地存储,COS提供了更低的成本和更高的可用性。除了标准存储以外,COS还提供成本更低的标准、低频、归档以及深度归档四种类型存储,根据数据需要访问的频率需求,将数据沉降至对应的存储类型,进一步降低成本。
4.3 基于COS的ClickHouse数据分层实现
在配置数据分层之前,我们提前准备如下环境:
- 本地存储:挂载增强型SSD硬盘,并格式化为本地文件系统,挂载到/data路径,用于存放热数据。
- COS存储桶:新建COS存储桶,用于存放冷数据,获取具有访问该存储桶权限账号的SecretId以及SecretKey。
4.3.1 配置ClickHouse磁盘及策略
首先我们需要配置/etc/clickhouse-server/config.d/storage.xml文件,在配置中的<disks>部分定义本地磁盘的路径以及COS存储桶的URL、访问账号的SecretId和SecretKey,同时在<policies>中定义名为<ttl>的策略,该策略中定义了<ttlhot>和<ttlcold>两个卷,分别包含本地存储以及COS存储桶。
以下是配置文件的详细内容(请根据实际场景替换本地路径以及COS的URL、access_key_id和secret_access_key):
<yandex>
<storage_configuration>
<disks>
<localdisk> <!-- disk name -->
<path>/data/</path>
</localdisk>
<cos>
<type>s3</type>
<endpoint>http://example-1250000000.cos.ap-shanghai.myqcloud.com/ck/</endpoint>
<access_key_id>AKIDxxxxxxxx</access_key_id>
<secret_access_key>xxxxxxxxxxx</secret_access_key>
</cos>
</disks>
<policies>
<ttl>
<volumes>
<ttlhot>
<disk>localdisk</disk>
<max_data_part_size_bytes>1073741824</max_data_part_size_bytes>
</ttlhot>
<ttlcold>
<disk>cos</disk>
<max_data_part_size_bytes>5368709119</max_data_part_size_bytes>
</ttlcold>
</volumes>
</ttl>
</policies>
</storage_configuration>
</yandex>
修改完配置文件之后,在clickhouse客户端重新加载配置后就能看到新配置的磁盘及策略:
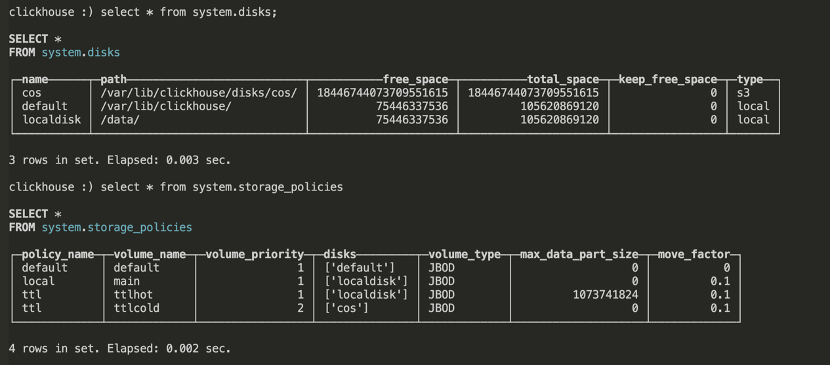
4.3.2 导入数据至ClickHouse
完成存储配置后,我们需要建立一个配置了TTL策略的表,并往表中导入数据以验证我们配置的分层策略。
这里我选择我们一个COS存储桶的清单作为导入的数据源,首先根据清单中各列的内容,在ClickHouse中新建一个名为cos_inventory_ttl的表,同时配置TTL策略,根据LastModifiedDate的值将热数据存放至ttlhot卷,而三个月以上的冷数据存放至ttlcold卷。
CREATE TABLE cos_inventory_ttl (
appid UInt64,
bucket String,
key String,
size UInt64,
LastModifiedDate DateTime('Asia/Shanghai'),
etag String,
storage_class String,
IsMultipartUploaded String,
Replicationstatus String
) ENGINE = MergeTree()
ORDER BY LastModifiedDate
TTL LastModifiedDate to volume 'ttlhot',
LastModifiedDate + toIntervalMonth(3) TO VOLUME 'ttlcold'
SETTINGS
storage_policy='ttl',
index_granularity=8192;
然后再将生成的清单文件下载到本地并解压成csv文件,然后将csv数据批量导入到ClickHouse数据库中:
for i in *.csv
do
echo $i;
cat $i |sed 's/\+08:00//g' |clickhouse-client -u default --password='123456' --query="INSERT INTO cos_inventory_ttl FORMAT CSV";
done
4.3.3 验证数据
数据导入完成后,我们首先查看总共导入的数据的行数:
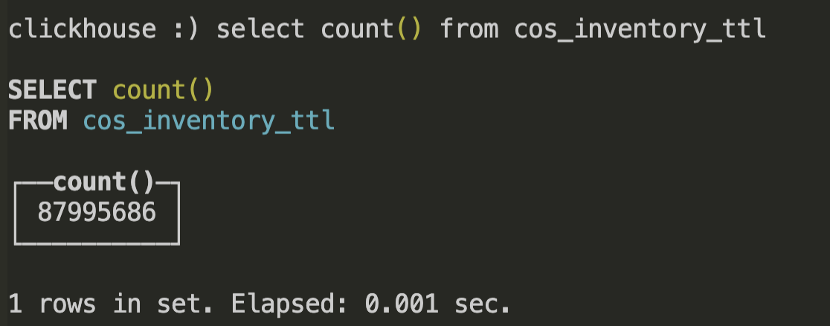
接下来,我们可以查询数据的分区存放的存储卷:
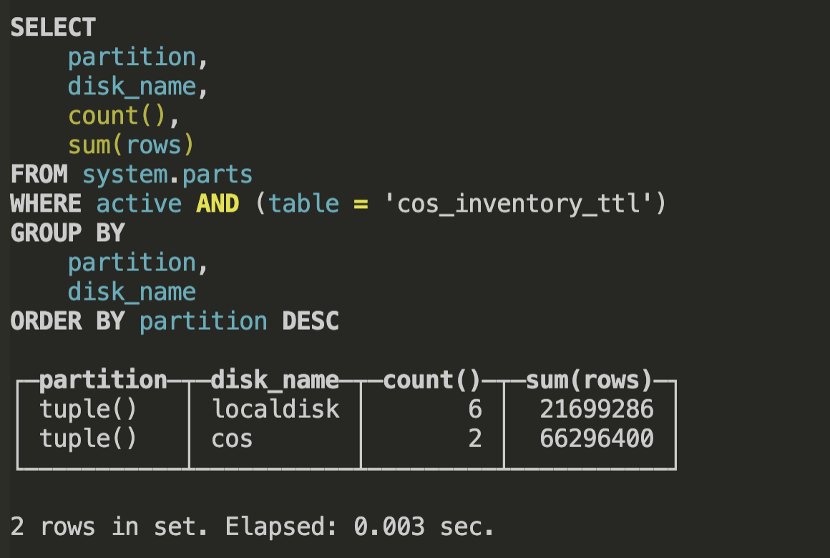
这里我们可以看到,数据已经按照预期存储在不同的磁盘上,其中约两千多万行数据存放在本地磁盘,约六千多万行数据存放在COS上。
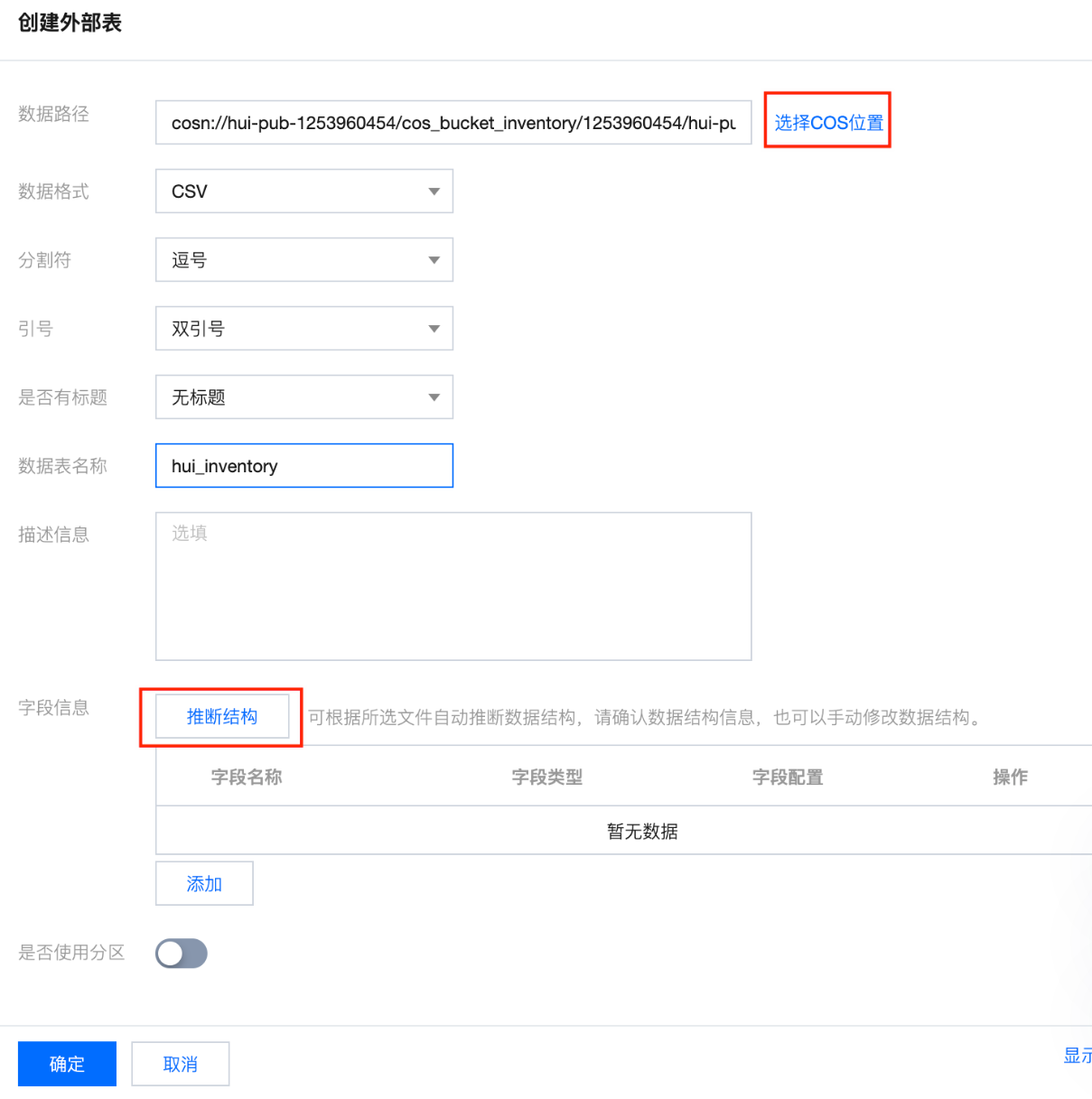
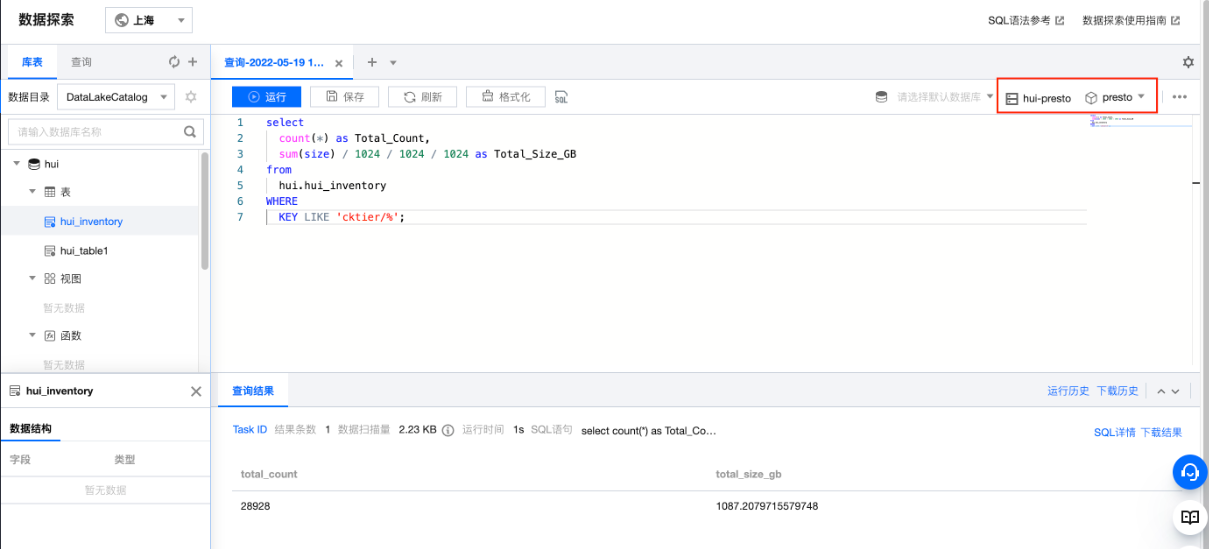
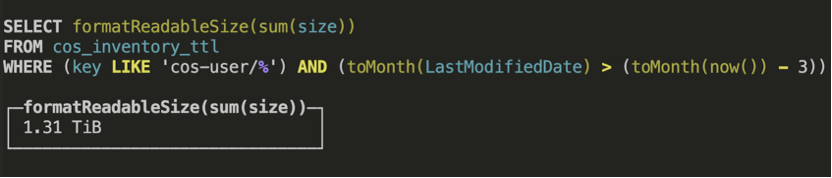
接下来我们可以做一个查询测试,这里我们统计一下cos_user/目录下最近三个月份生成的文件的总大小:
5 总结
通过配置在ClickHouse中配置不同的存储介质以及相应的策略,我们实现了ClickHouse数据在不同存储介质的自动存储。COS无限的存储容量以及超低的存储成本,使我们的ClickHouse集群在提供极致查询性能的同时又能以低成本的方式实现数据的长期存放。
更多腾讯云对象存储COS相关的内容,请参考我们的官网:https://cloud.tencent.com/document/product/436。
6 参考文档
https://altinity.com/blog/2019/11/27/amplifying-clickhouse-capacity-with-multi-volume-storage-part-1
https://altinity.com/blog/2020/3/23/putting-things-where-they-belong-using-new-ttl-moves
https://cloud.tencent.com/developer/article/1688478
https://mp.weixin.qq.com/s/9PZTws3KSzlybHXM6XC2hg